728x90
반응형
1) DataFrame.map() 메서드: element-wise(요소 단위) 적용
- 목적:
DataFrame의 각 스칼라 요소에 함수를 적용- element-wise 변환.
- 반환:
- 입력과 동일한 shape의 DataFrame.
- 주요 파라미터
func: 각 요소에 적용할 함수(호출 가능 객체).na_action='ignore': 결측값(NA)에는 함수를 적용하지 않음.na_action=None:- 기본값으로, 이 경우 NA값에도 함수 적용이 되며,
- 보통 NaN이 반환되지만 에러가 날 수도 있음.
- 비고:
- 이전에 사용되던
applymap은 deprecated. - 새 코드에서는 반드시
map사용해야 함.
- 이전에 사용되던
import pandas as pd
import numpy as np
df = pd.DataFrame({"A": [1, 2, np.nan], "B": [10, 20, 30]})
# 요소 단위로 제곱: 각 셀의 스칼라 값이 lambda의 인자로 전달됨
df_sq = df.map(lambda x: x**2)
# 결측값(NA)은 건너뛰기: NA에는 함수를 적용하지 않음
df_sq_skipna = df.map(lambda x: x**2, na_action="ignore")위의 예에서는 na_action의 차이가 없음.

다음은 차이가 있는 예임.
import pandas as pd
import numpy as np
s = pd.Series(["Alice", None, "Bob"])
# 기본값 (na_action=None) → None도 함수에 넘어가므로 에러 발생
try:
print(s.map(lambda x: x.upper()))
except Exception as e:
print("Error with na_action=None:", e)
# na_action='ignore' → None은 함수에 넘기지 않고 그대로 둠
print(s.map(lambda x: x.upper(), na_action="ignore"))
2) DataFrame.apply() 메서드: row-wise / column-wise(행/열 단위) 적용
- 목적:
- column 또는 row 에 해당하는
Series(또는ndarray)를 - 인자로 넘겨진 함수에 전달하여 변환/집계 처리.
- column 또는 row 에 해당하는
- 동작 축(
axis):axis=0(기본):- 각 column에 해당하는
Series가 함수 인자로 전달됨. - column 별로 처리가 이루어짐.
- 각 column에 해당하는
axis=1:- 각 row에 해당하는
Series가 함수 인자로 전달. - row 별로 처리가 이루어짐.
- 각 row에 해당하는
- 주요 파라미터
axis: 0(열 기준), 1(행 기준).raw=TrueSeries대신ndarray를 인자로 전달- 보다 빠른 처리가 가능
result_type: 결과 형식 제어'reduce':- 하나의 scalar값을 함수가 반환(각 Series마다 하나의 scalar).
- 기본모드.
'broadcast':- 각 Series마다 하나의 scalar값이 계산되나, Series의 shape에 맞추어짐.
- 즉 DataFraem의 shape가 입력과 같이 유지됨.
'expand':- 각 Series가 list,Series,배열 등의 여러 값을 반환할 경우,
- DataFrame 열/행이 확장됨.
다음은 간단한 예제임.
import pandas as pd
df = pd.DataFrame({"A": [1, 2, 3], "B": [10, 20, 30]})
# column-wise: 각 열(Series)이 lambda의 인자로 들어옴
col_sums = df.apply(lambda col: col.sum(), axis=0) # A=6, B=60
# row-wise: 각 행(Series)이 lambda의 인자로 들어옴
row_sums = df.apply(lambda row: row.sum(), axis=1) # [11, 22, 33]
# raw=True: 각 행의 값 배열(ndarray)이 인자로 들어옴 → 오버헤드 감소 가능
row_sums_fast = df.apply(lambda row_vals: row_vals.sum(), axis=1, raw=True)
result_type 에 대한 예제는 다음을 참고:
import pandas as pd
df = pd.DataFrame({
"A": [1, 2, 3, 4],
"B": [10, 20, 30, 40],
"C": [100, 200, 300, 400]
})
# reduce: 각 행에서 [min, max] 리스트 반환 → 리스트 전체가 하나의 값
reduce_res = df.apply(lambda row: [row.min(), row.max()],
axis=1, result_type="reduce")
# expand: 리스트의 각 요소를 열(column)로 확장
expand_res = df.apply(lambda row: [row.min(), row.median(), row.max()],
axis=1, result_type="expand")
expand_res.columns = ["min", "median", "max"]
# broadcast: 스칼라(min)을 행 전체에 broadcast
broadcast_res = df.apply(lambda row: row.min(),
axis=1, result_type="broadcast")
print("=== reduce ===", f"{type(reduce_res) = }")
print(reduce_res, end="\n\n")
print("=== expand ===", f"{type(expand_res) = }")
print(expand_res, end="\n\n")
print("=== broadcast ===", f"{type(broadcast_res) = }")
print(broadcast_res)
3) Series.apply() 메서드: element-wise(요소 단위) 적용
- 목적:
- Series의 각 원소(스칼라)에 함수를 적용
- element-wise 변환.
- 주요 파라미터
convert_dtype=True: 결과 dtype 자동 변환 시도.args,**kwargs: 함수에 추가 인자 전달.
import pandas as pd
s = pd.Series(["alice", "Bob", "CHARLIE"])
# 각 원소가 lambda의 인자로 들어옴 → 문자열 전처리에 적합
s_upper = s.apply(lambda x: x.upper()) # ['ALICE','BOB','CHARLIE']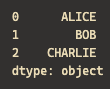
nums = pd.Series([1, 2, 3, 4])
squared = nums.apply(lambda x: x**2) # [1,4,9,16]
4) GroupBy.apply() 메서드: group-wise(그룹 단위) 적용
- 목적:
- 그룹화 후 각 그룹의 부분 DataFrame/Series를 함수에 전달
- 각 그룹별로 맞춤 연산 수행.
- 핵심:
- 함수에 넘어가는 첫 인자는
GroupBy객체가 아니라 - "그룹으로 나뉘어진(원문에선 split이라 "잘린" 으로 생각해도됨) 실제 데이터(부분 DataFrame/Series)"가 인자로 넘겨짐.
- 함수에 넘어가는 첫 인자는
- 최신 동작(중요):
include_groups=False파라미터를 명시하지 않으면FutureWarning발생 (Pandas 2.1+).include_groups=True: 그룹 기준 열/키 포함(현재 동작과 동일)된 상태로 함수에 넘겨짐.include_groups=False: 그룹 기준 열/키 제외(권장, 향후 기본값 예정)된 상태로 함수에 넘겨짐.- 경고 메시지 예:
FutureWarning: The default of include_groups will change to False in a future version.
- 그 밖의 자주 쓰는 옵션:
sort(그룹 키 정렬),dropna(NA 키 제외),observed(category 처리).
import pandas as pd
df2 = pd.DataFrame({
"team": ["A", "A", "B", "B", "B"],
"score": [10, 20, 30, 40, 50],
"round": [1, 2, 1, 2, 3],
})
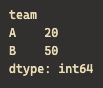
# 예1) 최신 라운드 점수만 추출: g는 'team'별 부분 DataFrame
latest_score = (
df2.groupby("team")
.apply(lambda g: g.sort_values("round").iloc[-1]["score"],
include_groups=False) # 권장: 그룹 기준 키 제외
)
# 예2) 각 그룹에서 점수 상위 1개 행만 반환: 복합 구조 반환 가능
top1_each = (
df2.groupby("team")
.apply(lambda g: g.nlargest(1, "score"),
include_groups=False) # 경고 회피 및 향후 호환성
)
# 예3) include_groups=True로 전달하면 그룹 기준 열이 함께 옴(비권장, 향후 기본 False)
with_keys = df2.groupby("team").apply(lambda g: g, include_groups=True)
핵심 요약 표
| 메서드 | 적용 단위(unit) | 함수 인자 | 주요 파라미터 | 비고 |
DataFrame.map |
element-wise (요소 단위) |
스칼라 | func, na_action |
applymap 대체(신규 권장) |
DataFrame.apply |
column-wise / row-wise (열/행 단위) |
Series 또는 ndarray (if raw=True) |
axis, raw, result_type |
축 단위 집계/가공 |
Series.apply |
element-wise (요소 단위) |
스칼라 | convert_dtype, args |
문자열/값 전처리 |
GroupBy.apply |
group-wise (그룹 단위) |
부분 |
include_groups, sort, dropna, observed |
include_groups=False 권장 |
728x90
'Python > pandas' 카테고리의 다른 글
| [Pandas] DataFrame 생성-다른 데이터 타입의 객체로부터 (0) | 2025.08.21 |
|---|---|
| [Pandas] 중복 데이터 삭제-drop_duplicates() 메서드 (0) | 2025.08.21 |
| [Pandas] groupby() 메서드 (0) | 2025.08.20 |
| [Term] pivot 이란? (0) | 2025.08.20 |
| [Pandas] pivot_table() 메서드 (0) | 2025.08.19 |



