
https://github.com/pytorch/xla
GitHub - pytorch/xla: Enabling PyTorch on XLA Devices (e.g. Google TPU)
Enabling PyTorch on XLA Devices (e.g. Google TPU). Contribute to pytorch/xla development by creating an account on GitHub.
github.com
다음 문서도 참고할 것.
https://github.com/pytorch/xla/blob/master/API_GUIDE.md
TPU로 PyTorch를 사용하기 위해서는 PyTorch / XLA 를 이용한다.
PyTorch/xla의 정의 다음과 같음:
“intermediate backend enabling eager-style PyTorch programming over XLA-compiled accelerators"
PyTorch/XLA 와 XLA (Accelerated Linear Algebra)란?
PyTorch/XLA란 쉽게 정리하면,
PyTorch로 구현된 model 및 PyTorch code 들을
- cpu와 gpu 를 넘어서서
- XLA (Accelerated Linear Algebra) 를 지원하는 H/W 상에서
- 동작하도록 해 주는
- PyTorch 코드와 XLA 컴파일러를 연결해주는 백엔드 인터페이스
XLA를 지원하는 대표적인 device는 바로 구글의 TPU(Tensor Processing Unit)임:
- XLA는 GPU, CPU도 지원하지만
- GPU나 CPU는 XLA 외에도 다른 대안이 있음 (MKL, cuDNN등 라이브러를 통해 native로 동작 가능).
- 하지만, TPU에선 XLA 외엔 다른 대안이 없음:
- TPU는 XLA컴파일러를 통해 최적화된 HLO를 연산단위로 삼아 동작하도록 설계됨.
XLA 는 딥러닝용 연산을 최적화해 특정 가속기(대표적인 예가 TPU)에서 실행 가능한 코드로 변환하는 컴파일러
- TensorFlow, JAX, PyTorch/XLA가 사용하는 domain-specific compiler
- HLO(High-Level Operation) IR을 기반으로 최적화
- backend로 CPU, GPU, TPU를 선택할 수 있음
- 본질적으로 NumPy/Deep learning ops를 XLA를 지원하는 가속기상에서 동작하는 고성능 기계어로 변환하는 컴파일러
참고
IR은 Intermediate Representation(중간 표현)의 약자:
- 컴파일러가 소스 코드와 기계어 사이에서 사용하는 추상화된 표현 형태를 가리킴.
- HLO는 TensorFlow/PyTorch 같은 Framework와 H/W 전용 기계어 사이에 존재하며 이 둘을 연결함.
- XLA는 IR로 HLO(Hight Level Operations) 라는 연산 그래프 형태의 표현을 사용
ops는 operations(연산)의 약자:
- 즉, 딥러닝 프레임워크나 NumPy가 제공하는 개별 연산자(Operator) 를 의미
XLA는 가속기 하드웨어 API 위에서 동작하는 상위 컴파일러이고,
PyTorch/XLA는 PyTorch 연산을 XLA가 이해하는 HLO로 변환해 가속기에서 실행되도록 연결해주는 브리지(back-end)이다.
PyTorch/XLA / TensorFlow / JAX
↓
XLA (deep-learning compiler)
↓
TPU runtime
↓
TPU HW
위의 계층 구조를 표로 정리하면 다음과 같음:
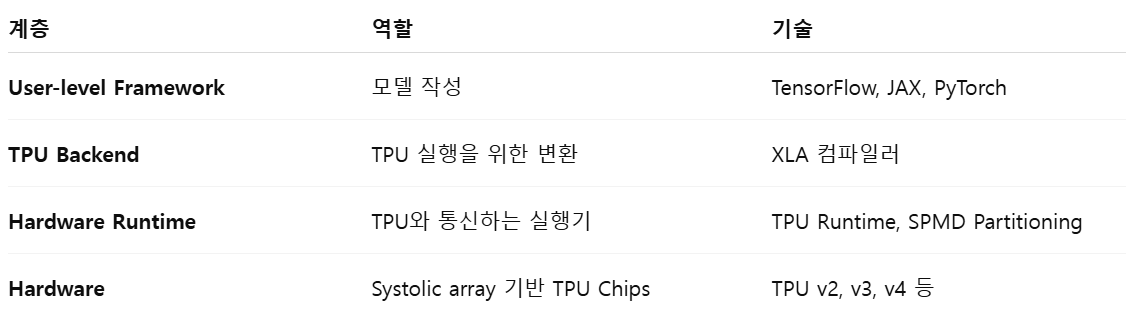
XLA를 보다 자세히 보면 다음과 같음:
- 입력: ML framework의 연산 그래프 (JAX, TensorFlow, PyTorch/XLA 등)
- IR: HLO(High-Level Operation) - XLA가 내부에서 사용하는 IR
- 최적화: fusion, tiling, layout, CSE, SPMD partitioning 등
- 출력:
- CPU용 LLVM IR
- GPU용 LLVM => PTX 변환
- TPU용 저수준 명령어
PyTorch로 한정할 경우,
- PyTorch는 기본적으로 CPU와 GPU를 지원하지만,
- XLA를 통해 TPU와 같은 추가 하드웨어 가속기에서도 효율적으로 동작할 수 있음.
작업과정은 다음과 같음:
- PyTorch/XLA는 PyTorch 계산 그래프를 XLA의 HLO로 변환하고,
- XLA 컴파일러는 이 HLO를 TPU용 저수준 실행 코드로 컴파일하여
- TPU Runtime에서 실행되도록 한다.
TPU는
사실상 XLA based Framework에 의존하고 있음.
PyTorch XLA의 주요 역할:
- 하드웨어 추상화:
- PyTorch XLA는 PyTorch와 TPU 사이의 중간 계층으로 작동
- PyTorch 코드가 TPU 상에서 실행될 수 있게 해 줌.
- 개발자는 TPU의 복잡한 세부 사항에 신경을 쓰지 않고, PyTorch 코드 작성에 집중하며 XLA가 나머지를 처리해주는 방식.
- 성능 최적화:
- XLA는 복잡한 tensor 연산을 최적화하여 TPU와 같은 XLA를 지원하는 하드웨어에서 효과적으로 실행시켜줌.
- 이는 메모리 접근 최적화, 병렬 처리 최적화 등을 통해 이루어짐.
- 확장성:
- TPU는 높은 병렬 처리 능력을 가지고 있고 특히 GPU 대비 보다 큰 메모리 지원을 함.
- XLA를 통해 이러한 TPU의 장점을 효과적으로 활용할 수 있음.
- 이는 큰 규모의 머신 러닝 모델을 훈련하거나, 대량의 데이터를 처리할 때 특히 유용.
- 이식성:
- PyTorch XLA를 사용하여 XLA를 지원하는 시스템에서 기존의 PyTorch 코드를 최소한의 변경으로실행할 수 있음.
Colab의 TPU사용하기
TPU를 device 객체로 얻는 과정(device = torch_xla.device()) 만이 다를 뿐,
이후는 일반 PyTorch의 코드와 차이가 없음.
- GPU로 데이터와 모델을 보내는 것처럼, TPU에 해당하는 device로 보내면 됨.
- 단, optimizer.step() 이 CPU/GPU 에선 해당 kernel을 즉시 실행하는 방식이나
- PyTroch/XLA의 경우 lazy execution이라는 라는 차이가 존재하므로,
명시적 tigger를 수행하는 torch_xls.core.xla_model 모듈의 mark_step() 을 호출해줘야 함. - 최근엔 step()과 mark_step() 을 모두 처리하는 helper function인 optimizer_step(optimizer) 가 권장됨.
다음 gist를 참고할 것.
https://gist.github.com/dsaint31x/8290dab796f1dc2382ef7245abaa32d7
dl_torch_tpu_xla.ipynb
dl_torch_tpu_xla.ipynb. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
같이보면 좋은 자료들
2025.02.28 - [CE] - [DL] GPU Acceleration 기술 소개
[DL] GPU Acceleration 기술 소개
1. 대표적 GPU 가속 기술현재 가장 많이 사용되고 있는 GPU기반의 가속기술은 다음과 같음:Compute Unified Device Architecture (CUDA): NVIDIAMetal Performance Shaders (MPS): AppleRadeon Open Compute (ROCm): AMDDirect Machine Learn
ds31x.tistory.com
https://dsaint31.me/mkdocs_site/CE/ch04/ce04_51_gpu_tpu/?h=tpu
BME
Graphics Processing Units 다음 URL을 확인할 것. 아래 그림은 CPU와 GPU의 차이점을 모식도로 표현함. 병렬처리에 최적화된 GPU의 특징인 다수의 core 를 볼 수 있음. GPGPU의 경우 병렬화를 DLP(Data Level Parallel
dsaint31.me
'Python' 카테고리의 다른 글
| [DL] PyTorch: Autograd (Basic) (1) | 2024.03.22 |
|---|---|
| [DL] PyTorch: view, data, and detach (0) | 2024.03.22 |
| [DL] Storage: PyTorch 텐서를 위한 메모리 관리 (0) | 2024.03.21 |
| [Tensor] NaN Safe Aggregation Functions (0) | 2024.03.20 |
| [Tensor] vectorized op. (or universal func) (0) | 2024.03.19 |


